数据库设计
- 需求分析
- 概念设计:进行建模,决定数据库应该要有哪些实体,实体要有哪些属性。比如使用ER模型进行设计。
- 逻辑设计:将概念设计得到的模型映射到数据所使用的模型上。
- 物理设计:包括文件组织的形式以及内部的存储结构。
设计选择
在设计时,我们必须确保避免两个主要的缺陷:
- 冗余
- 不完整
更大还是更小:
- 更大的模式 比如department模式与student模式进行合并,得到两个模式的连接结果dept_stu 问题:
- 数据冗余
- 有些情况无法表示
- 更小的模式: 如何发现一个模式需要分解成n个更小的模式? 函数依赖 定义这样的一条规则:如果存在模式(dept_name,budget),则dept_name可以作为主码,那么这就叫函数依赖 记作:x → y 有损分解:分解过后无法表达一些重要的信息。 无损分解:上面取反
设计异常
不符合范式的关系
- 冗余数据
- 修改异常
- 删除异常
- 插入异常
ER模型
- 实体:对象
- 属性:实体通过一组属性来表示,每个属性都有一个值
- 每个属性都有一个可取值的集合,称为该属性的域,属性类型的划分:
- 简单和复合
- 单值和多值
- 派生属性
- 每个属性都有一个可取值的集合,称为该属性的域,属性类型的划分:
- 实体集:实体构成的集合
- 联系:多个实体间的相互关联,实体在联系中扮演的功能称为实体的角色,联系也可以具有描述性属性
- 联系集:相同类型联系的集合
扩展
- ISA
- Part-Of
约束
映射基数
- 一对一
- 一对多
- 多对一
- 多对多
参与约束
- 全部参与
- 如果实体集E中的每个实体都参与到联系集R的至少一个联系中
- 那么E在R就是全部参与
- 部分参与
码
实体的码是一个足以分区每个实体的属性集,同样,码也可以用于唯一标识联系
从实体集中删除冗余属性
当决定好实体集后,必须挑选合适的属性
ER图
基本结构
- 分割成两部分的矩形:实体集
- 菱形:联系集
- 未分割的矩形:联系集的属性
- 线段:实体集与联系集的连接
- 虚线:联系集到联系集的连接
- 双线:实体在联系集中的参与度
- 双菱形:连接到弱实体集的标志性联系集
- 带箭头的线:代表箭头所指的那方实体映射基数为1
- 不带箭头的线:代表箭头所指的那方实体映射基数为多
复杂的属性
比如 Address
- city
- street
角色
通过在菱形和矩形之间的连线上进行标注来表示角色
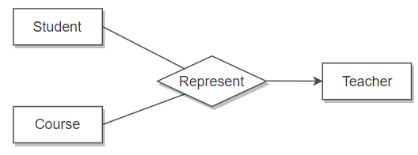
非二元的联系集
即一个联系连接了两个以上的实体
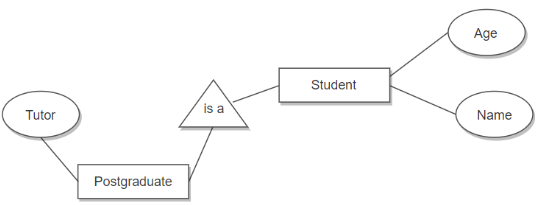
继承关系
弱实体集
- 没有足够的属性以形成主码的实体集称为弱实体集
- 有主码的实体集称为强实体集
转换为关系模式
- 逻辑结构设计
具有简单属性的强实体集表示
比如实体集student,有三个属性:ID、name、credit,可以转换成如下关系模式:
student(ID,name,credit)
具有复杂属性的强实体集的表示
比如student有一个属性address,又有子属性city,street,那么可生成关系模式:
student(ID,name,credit,city,street)
弱实体集的表示
设A为一个弱实体集,B为A所依赖的一个强实体集。那么可以创建一个关系模式:
B(a1,a2,a3,x),其中a1,a2,a3为B的属性,x为B到A的外键约束
联系集的表示
设R为联系集,a1,a2...an为参与R的实体集构成的属性集合,b1,b2...bn为R的属性,则R的属性为:
{a1,a2..an}∪{b1,b2,...bn}
如何选取主码:
- 对于多对多的二元联系:参与实体集的主码属性并集成为主码
- 对于一对一的联系集:任何一个实体的主码都可以选作为主码
- 对于多对一或者一对多:多的那一方的实体集可以选取作为主码
模式冗余
一般情况下,连接弱实体集与其所依赖的强实体集的联系集模式是冗余的。
模式的合并
- 在一对一的联系的情况下:联系集的关系模式可以跟参与联系的任何一个实体集的模式进行合并
ER设计问题
用实体集还是用属性
什么构成实体集,什么构成属性?这个问题要根据现实情况进行回答。
- 一个常见的错误是用一个实体集的主码作为另一个实体集的属性,而不是用联系
- 另一个错误是将相关实体集的主码属性作为联系集的属性
用实体集还是用联系集
一个原则是:当描述发生在实体间的行为时采用联系集
二元还是n元联系集
数据库中的联系通常都是二元的。
一些非二元的联系可以通过拆分分为二元联系,但是这样做,有时并不那么自然
联系属性的布局
属性放到哪里,是实体集还是联系集?这也是要根据实际情况进行决定
扩展的E-R特性
特化
自顶向下的,可以看做OOP当中父类转换成子类的这么样一个过程
概化
同上,类似于OOP中的向上转型
属性继承
高层实体集的属性可以被底层实体集继承
概化上的约束
数据库设计者可以决定哪些实体能成为给定低层实体集的成员,条件可以如下:
- 条件定义
- 用户定义
聚集
E-R模型的一个局限性在于它不能表达联系间的联系。聚集是一种抽象,它把联系视为高层实体,这样就可以表达联系之间的联系了
转换为关系模式
概化的表示
- 为高层实体集创建一个模式,为每个低层实体集创建一个模式
- 如果概化是不相交并且完全的,就是说不存在同时属于两个同级的低层实体集的实体
聚集的表示
聚集的主码是定义该聚集的联系集的主码
其他建模方式表达
范式
范式最重要的就是保证数据之间的关联一致性及控制数据冗余,这种保证会影响数据库的性能 所以在大数据量、高并发的场景下提倡反范式以此来提升性能
原子域与第一范式
一个域是原子的,如果该域的元素被认为是不可分的单元,我们称一个关系模式R属于第一范式。 简单来说:所有关系模式数据库都符合第一范式
第二范式
每个非主属性完全函数依赖于键码,说人话就是数据行的每个属性都可以由主键查询得到
函数依赖
码和函数依赖
一个关系满足需求定义的现实世界约束,称为关系的合法实例
- 给定R的一个实例,我们说这个实例满足函数依赖x → y 的条件是:对于实例中的所有元组t1,t2 ,若t1[x] = t1[x] ,则t1[y] = t2[y],说人话就是 一个关系R中有两个属性x和y,如果x能够唯一确定y的值就说y函数依赖于x
- 如果R中的每个合法实例都满足函数依赖,则我们说该函数依赖在R上成立 有两种方式使用函数依赖:
- 判定关系的实例是否满足给定函数依赖集F
- 说明合法关系集上的约束 平凡函数依赖:如果y ⊆ x,则称 x→y 的函数依赖是平凡的 用F+表达F集合的闭包,也就是能够从给定F集合推导出来的函数依赖集合,说人话就是平凡函数依赖是指一个属性集(关系属性的集合)能够决定它的子集,也就是说,当一个属性集的值相同时,它的子集的值也一定相同
BC范式
属于BC范式的条件是: 对于F+中所有形如a→b的函数依赖(a ⊆ R,b⊆R ),下面至少有一项成立:
BC范式就是要求一个表中的每个属性都只跟主键有关,而不跟其他属性有关
- a → b是平凡的函数依赖(b ⊆ a)
- a是模式R的一个超码 分解不属于BCNF的一般规则: 设R为一个不属于BCNF的一个模式,则存在至少一个非平凡的函数依赖a→b,其中a不是R的超码,我们用两个模式取代R:
- (a ∪ b)
- (R - (b - a )) 进行迭代直到得到一个BCNF模式集合
BCNF和保持依赖
由于设计使得函数依赖的强制实施在计算很困难,因此称这个设计不是保持依赖的
第三范式
属于第三范式的条件,下面至少一项成立:
- a → b是一个平凡的函数依赖
- a 是R的一个超码
- b - a的每个属性都包含于R的一个候选码中
满足BC范式的关系模式一定满足第三范式,第三范式与 BC 范式的区别在于,BC 范式的依赖是可以推导的,而第三范式依赖只是直接有关:第三范式就是要求一个表中的每个属性都只跟主键直接有关,而不跟其他属性有关
其他范式
ER模型和规范化
- 正确定义的 ER 图就不需要太多进一步的规范化
属性和联系的命名
- 数据意义相同上的字段使用相同命名最佳
- 大部分联系名都是两个实体名之间加下划线
为性能去规范化
有些范式可能需要在修改或者查询数据时进行更多的操作,这会影响性能,常见去范式提高性能的方式:
- 信息冗余,如在订单表存放购买人信息
- 物化视图,虽然还有冗余,但是一致性的维护是由数据库来进行
函数依赖理论
函数依赖集的闭包
逻辑蕴含: A → B,B → h 那么 A → H被逻辑蕴含
Amstrong 公理
一组关于函数依赖的基本规则,它们可以用来推导出一个关系模式中所有的函数依赖
- 自反律:若a为一属性集且 b ⊆ a,则a → b成立
- 增补律
- 传递律
- 合并律
- 分解律
- 伪传递律
属性集的闭包
如果 a → B,我们称属性B被a函数确定
正则覆盖
无损分解
R1,R2是R的分解,如果用R1,R2替代R没有信息损失,则该分解是无损分解
保持依赖
分解算法
BCNF分解
3NF分解
BCNF和3NF的比较
应用函数依赖进行数据库设计的目标:
- BCNF
- 无损
- 保持依赖
使用多值依赖的分解
多值依赖
函数依赖有时成为相等依赖 多值依赖成为元组产生依赖 设R为关系模式,让a ⊆ R 且 b ⊆ R 多值依赖 a -> -> b在R上成立的条件是:
4NF分解
数据库设计的其他方面
- 数据约束和关系数据库设计
显式声明约束的优点:
- 自动保持数据的一致性
- 一些约束在数据库模式的设计中非常有用
- 当然也可以提高访问效率
缺点:
在数据更新时,执行约束会在性能上带来潜在的高代价
使用需求:查询、性能
主要的两个度量方法:
- 吞吐量
- 响应时间
时态数据建模
时态数据时具有关联时间段的数据 快照快照是指一个特定时间点上该数据的值,除了可以将每行记录关联一个时间段来代表有效性之外,也有专门的时序数据库用来解决这种需求,金融系统用的很多
授权需求
不同的用户与组织能看到数据会受到不同的限制,这块是认证授权需要干的
数据流、工作流
工作流表示一个流程中的数据和任务的组合
当用户在执行工作流中的任务时,工作流会与数据库系统进行交互,除了工作流操作的数据之外,数据库还可以存储工作流自身的数据
数据库加密
- 数据库层面的加解密 MySQL的AES_ENCRYPY/AES_DECRYPT HEX/UNHEX
- 应用层处理
- 传输层处理 SSL
数据库设计的其他问题
数据库设计要求设计者可以预先估计一个组织将来的需求,设计出的模式在需求发生变更时只要做最少的改动即可满足要求。
实践中的一些问题
没有唯一键约束
业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引
如果没有唯一索引,很容易会被插入重复数据
执行delete没带查询条件
执行删除操作时,要开启事务,同时要先查询核对影响的行数和数据准确性,再执行删除操作 ;执行删除操作后再次核实,如果情况不对立即回滚
表结构修改没有兼容老数据
比如增加了一个非null字段
时效性要求极高的场景查了备库
备库存放的数据可能不是最新的数据
悬停时间较长的事务被kill
表新增了供查询的字段,却没建索引,导致慢查询
数据库技术选型
- 确定数据库类型 db-engines
MySQL 数据库设计
命名规范
数据库:
- [a-z ][0-9] _
- 不超过30字符
- 备份数据库可以加自然数
表:
- [a-z ][0-9] _
- 相同关系的表可以加相同的前缀
字段:
- [a-z ][0-9] _
- 多个单词使用下划线分割
- 每个表必须有自增主键(默认系统时间)
- 关联字段名尽可能相同
字段类型规范
- 使用较少的空间来存储
- ip最好使用int
- 固定长度的类型使用char
- 最好给默认值
索引规范
- 加一个index后缀
- 为每个表创建主键索引
- 复合索引慎重
范式规范
- 必须满足第二范式
- 尽量满足第三范式
设计原则
核心原则:
- 不在数据库做运算
- 控制列数量(20以内)
- 平衡范式与冗余
- 禁止大SQL
- 禁止大事务
- 禁止大批量
字段原则:
- 用好数据类型节约空间
- 字符转为数字
- 避免使用NULL
- 少用text
索引原则:
- 不在索引列做运算
- innodb主键使用自增
- 不用外键
SQL原则:
- 尽可能简单
- 简单事务
- 避免使用触发器,函数
- 不使用select *
- OR改写成IN或UNION
- 避免前%
- 慎用count(*)
- limit高效分页
- 少用连接join
- group by
- 使用同类型比较
- 打散批量更新